jdk logger는 java.util.logging 패키지에 구현되어 있다. Logger.getLogger(String name) 메서드를 통해 로거 인스턴스를 가져오는 방식이고, 최소 로그 레벨과 핸들러를 지정하게 된다. jdk logger가 제공하는 로그 레벨은 다음과 같다. 이 중 severe, warning, info 정도의 레벨로 로그의 위험도를 구분하는 것이 일반적일 것이다.
• SEVERE: a serious failure
• WARNING: a potential problem
• INFO: reasonably significant informational message
• CONFIG: hardward configuration
• FINE, FINER, FINEST: tracing information
핸들러는 여러 개 지정할 수 있다. 일반적으로 ConsoleHandler와 FileHandler가 주로 사용된다.
• ConsoleHandler: for writing to System.err
• FileHandler: for writing to either a single log file, or a set of rotating log files
• StreamHandler: for writing to an OutputStream
• SocketHandler: for writing to a TCP port
• MemoryHandler: for writing to memory buffers.
로거 인스턴스에 getHandlers() 메서드를 호출하면 로거에 연결된 핸들러 정보를 배열로 받아올 수 있다. 핸들러 정보를 가져와 필요하지 않은 핸들러라면 제외시킬 수 있을 것이다.
// 파일 핸들러를 제거한다면, Logger logger = Logger.getLogger(name); Handler[] handlers = logger.getHandlers(); for (Handler h : handlers) { if (h instanceof FileHandler) { if (!doFileLog) { h.flush(); h.close(); logger.removeHandler(h); } } }
또는 필요한 핸들러는 언제든지 추가할 수 있다. 파일 핸들러는 rotating을 지원하는데 로그 파일의 용량과 최대 개수를 생성자에 지정할 수 있다.
FileHandler fileHandler = new FileHandler(logFileName, ROTATE_SIZE, ROTATE_COUNT, true); logger.addHandler(fileHandler);
파일 핸들러와 같은 것들은 애플리케이션이 종료될 때 같이 닫혀야 한다. Runtime의 addShutdownHook에 파일 핸들러를 닫아주는 쓰레드를 지정해주면 될 것이다.
final class FileHandlerCloser implements Runnable { private final FileHandler fileHandler; private FileHandlerClose(FileHandler fileHandler) { this.fileHandler = fileHandler; } public static void addHandler(FileHandler fileHandler) { Thread closer = new Thread(new FileHandlerCloser(fileHandler), fileHandler.toString()); Runtime.getRuntime().addShutdownHook(closer); } public void run() { fileHandler.flush(); fileHandler.close(); } }
마지막으로 각 핸들러에겐 기록할 로그 형식을 지정해주어야 한다. 추상 클래스 Formatter를 구현하면 된다. 구현할 메서드는 하나다.
public String format(LogRecord record);
인자로 전달되는 record 객체로부터 로그를 남긴 클래스 이름과 메서드 이름을 알 수 있다. 라인 번호까지 알고 싶으면 스택 트레이스에서 정보를 빼오면 된다. 그리고나서 record에 담긴 정보를 문자열로 내보내면 될 것이다.
int lineNumber = 0; StackTraceElement[] stackTraceElement = Thread.currentThread().getStackTrace(); for (int i = 0; i < stackTraceElement.length; i++) { if (stackTraceElement[i].getClassName().compareTo(record.getSourceClassName()) == 0 && stackTraceElement[i].getMethodName().compareTo(record.getSourceMethodName()) == 0) { lineNumber = stackTraceElement[i].getLineNumber(); break; } } // [Time] [Level] [ClassName:MethodName:LineNumber] [Message] StringBuilder builder = new StringBuilder(1000); builder.append(new SimpleDateFormat("[yyyy/MM/dd/HH:mm:ss]").format(new Date(record.getMillis()))); builder.append(" [").append(record.getLevel()).append("]\t"); builder.append("[").append(record.getSourceClassName()).append(":"); builder.append(record.getSourceMethodName()).append(":"); builder.append(lineNumber + "]\t["); builder.append(formatMessage(record)).append("]\r\n"); return builder.toString();
jdk logger의 전체 구조는 아래 이미지와 같다. 근사하다.
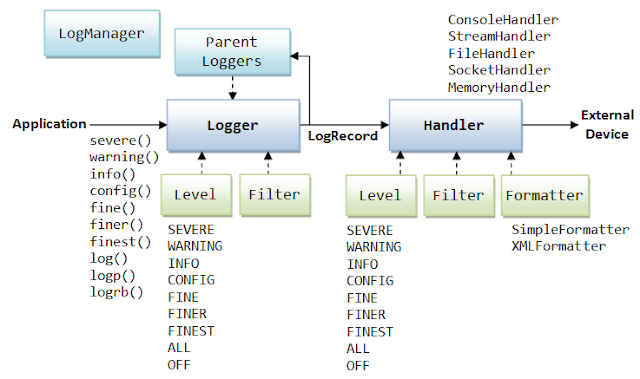

이미지 출처는